
Best Practices for Developing Content Policies and Procedures
 Many organizations are feeling the pain of content creation and management. This stems from systemic and process-driven challenges that, if solved, would present a significant opportunity for businesses to leverage their existing content to improve consistency and create efficiencies for service-level teams.
Many organizations are feeling the pain of content creation and management. This stems from systemic and process-driven challenges that, if solved, would present a significant opportunity for businesses to leverage their existing content to improve consistency and create efficiencies for service-level teams.
Improving consistency across an organization starts with the concept that standardization is fundamental to optimizing content management. Without standards or guides, teams duplicate efforts and create opportunities for inconsistencies throughout their documentation.
Creating standards, using standardized technology, and implementing an underlying format for organizational information are important — and standards for how we write are equally important.
Many organizations in different sectors already have various standards — but what we really need to look at is: are our standards really suited to collaboration, are they creating opportunities for leads, and how do we make information intelligent or smart? Are you making content that is findable, usable, and reusable?
Standards normally originate from the dedicated writing teams within organizations. Determining how these teams function and what role they play in generating business opportunities is an important step toward establishing a strong set of procedures and standards. Often, within a large organization, the policy and procedure writers make up a very significant portion of this process. So looking at how we address structured authoring, or content standards, for content teams and for policy and procedure writers is a challenge many businesses face.
Creating content standards is certainly one part of the process. But, we need to also understand and develop processes for the content creation process. Often, many departments will have touchpoints with various types of documents like Word documents or PDFs. Having an undefined or difficult review, approval, and publishing process holds up delivery and ultimately, the usefulness of this information. Our systems need to facilitate the development and review of content, getting it into the right hands faster.
So how do we get there?
Breaking the ‘Whole Document’ Paradigm
 One of the methods to create more accessible content is structured authoring, which breaks the “whole document” paradigm that we’ve all come to know.
One of the methods to create more accessible content is structured authoring, which breaks the “whole document” paradigm that we’ve all come to know.
When an author’s content gets buried in Word or PDF files that live in a document management system or network drive, they become very difficult to access.
Structured authoring paves the way for topic-based authoring, the process of breaking modular, iterative, information into smaller units and managing them as discrete units. We start with creating units such as policies, instructions, procedures, and process documents. We break them down into initial topics or modules that deal exclusively with one policy, one instruction, or one set of instructions and we add metadata to these individual topics that track reuse, approval, version, and flexibility. This process helps us manage this information more effectively and ensures the right information gets into the right hands of the right people at the right time.
Once topics are created, we place them into a repository where they reside and can be used to create any number of different information products. Again, the core concept is being able to take these topics and reuse them for different information products. What we are creating through this process are opportunities for the reusability of information by breaking information down into topics.
We can then take this information and assemble it into a policy manual, for instance. Or, we can take that same information or different pieces of that information and create online assistance or other sorts of instructions for people within the organization.
What effect does this process have on the overall corpus of your content?
Change is a process and we can only track this well if we’re tracking information as a topic. When we’re tracking topics with fine-grained metadata we can see how information performs in different contexts, be it an email or 40-page document. This level of visibility comes with benefits and challenges. The benefits include opportunities for collaboration and finer control over the content. This allows us to better balance the workload for dedicated teams.
The challenge when we break large documents down into topics, is the volume of information that needs to be managed. With more data, comes more moving pieces. To be effective, we need CCMS technology to be able to effectively use this content. Simply putting our content into network drives is not a good solution. Managing these pieces and making them available to the whole organization is a necessary process to help get us to where we need to be with enterprise policies and procedures.
 When we look at what cutting-edge organizations are doing regarding structured authoring we find that there are some interesting approaches. There are some working with HTML content, so they have policies on their SharePoint system or they’re using a web CMS for content management. These approaches can be a good starting point. Some organizations are using a writing methodology called information mapping.
When we look at what cutting-edge organizations are doing regarding structured authoring we find that there are some interesting approaches. There are some working with HTML content, so they have policies on their SharePoint system or they’re using a web CMS for content management. These approaches can be a good starting point. Some organizations are using a writing methodology called information mapping.
Developed in the 1960s, information mapping has resulted in newer innovations in structured authoring. Underlying many of these approaches is XML or Extensible Markup Language. XML is an open standard for information that’s easily read by both people and machines. Although XML is everywhere, its complexity can be intimidating when we introduce it into an enterprise organization. Although it is complex, many people are working with XML without ever knowing it when they use Microsoft Word, Excel, or even PowerPoint.
 Moving to structured authoring serves two fundamental needs.:
Moving to structured authoring serves two fundamental needs.:
The first is to make information easier for people to use, and make it more findable, more understandable, and easier to retain.
The second suggests that having unstructured content, from a technological perspective, makes information easier to integrate into other systems. It is easier to index, search, and process in a variety of ways. And of course, it is available for reuse.
As we transition towards more intelligent machines we are going to need intelligent content.
Five Types of Content
 To create more intelligent content we have broken information down into five distinct types.
To create more intelligent content we have broken information down into five distinct types.
By breaking this information down, we can assemble it into any piece of structured content that we would use for policies and procedures, and other types of documentation.
- Reference: Reference is something that describes things the reader needs to know.
- Task: This type of information is used for instructing the reader on how to do things.
- Concept: A concept type of information is the information we reserve for explaining things that the reader needs to understand.
- Process: Process is used to demonstrate to the reader how things work.
- Principle: Principle types of information advise the reader about things they need to do or not. The principal type is the core for policy documents.
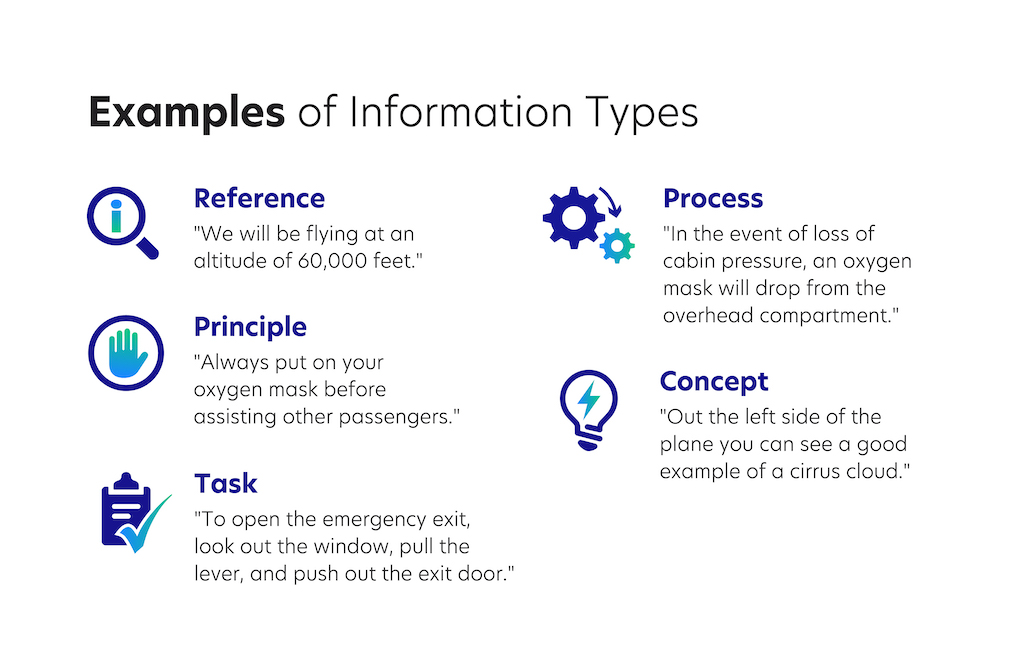
As an example, let’s look at a typical flight safety briefing:
If you’ve seen this presentation given by the cabin crew, you know that you are offered a piece of reference information: we will be flying at an altitude of 60,000 feet. This is “nice to know” information, but the listener is not expected to do anything.
Next we have the principal type of information, “always put your oxygen mask on before assisting other passengers”.
Task information: to open the emergency exit, look out the window, pull the lever, and push out the exit door.
Process information: In the event of loss of cabin pressure, oxygen masks will drop from the overhead compartment.
And then finally, we have the concept type: on the left side of the plane, you can see a good example of a cirrus cloud.
Information types are important because they inform writing styles. Having access to sophisticated content and document management technology is great. But if we’re not writing to leverage that technology, then we’re missing the mark.
Writing with different information types informs how we label a title, a block, or topics of information. They tell us what type of voice intensity, and they tell us what structures are necessary to best convey these different types of information in different circumstances. And, they provide a set of rules for blocks of information that are standardized around these writing styles. These rules and standardization allow us to create better-structured building blocks for information that we can then use to assemble larger documents. From a single source of truth, we can reconfigure content using the same information for different purposes.
Is your content ready for what comes next?
There’s no time like the present to get started with preparing your content for the next wave of technologies so that you can move forward with intelligent and scalable solutions — Contact us to start the conversation!
About the Author
 Rob Hanna co-founded Precision Content in 2015 to pursue his goals to produce tools, training, and methods that will help organizations make their high-value content instantly available to all that need it including customers, staff, partners, and even other information systems that need to consume that content. Driving this development is the Precision Content® Writing Methods, based on the best-available research over the last 50 years into how the brain works with information. Today Rob leads his highly-skilled team of content strategists, information architects, writers, trainers, and developers to serve the needs for digital transformation for businesses across North America.
Rob Hanna co-founded Precision Content in 2015 to pursue his goals to produce tools, training, and methods that will help organizations make their high-value content instantly available to all that need it including customers, staff, partners, and even other information systems that need to consume that content. Driving this development is the Precision Content® Writing Methods, based on the best-available research over the last 50 years into how the brain works with information. Today Rob leads his highly-skilled team of content strategists, information architects, writers, trainers, and developers to serve the needs for digital transformation for businesses across North America.